FECrash 함수형 프로그래밍 스터디 1부가 끝이 났다 오늘로 <쏙쏙 들어오는 함수형 코딩>책
카카오 엔터프라이즈의 테오 가 강의하고, 넥스트 유니콘 파랑 이 주최한 스터디.
강의 2~30분, 팀별활동 1시간 30분, 총 2시간씩
매주 목요일 저녁 진행되었다. -> 깃헙 보러가기
모두가 알찬 내용을 기대하고 온 만큼 열정적으로 참여하셨다.
예상 스터디 기간은 8~10주 로, 1부와2부 로 나뉘어 진행된다고 한다.
1부 는 함수형 프로그래밍의 개념 및 필요성, 기초 활용법 에 대해 팀으로 예제를 풀며 익히는 식으로 진행되었다.
2부 부터는 쿼리 등 함수형 프로그래밍을 위해 더 함수를 잘 분리하는 심화 방법 을 배운다고 한다.
매주 리팩토링 과제 가 진행되며, 마지막 에는 라이브러리를 만들어 보는 것 으로 마무리 된다고 한다.
오늘(1/5, 2023)을 기준으로 1부가 끝이 났다 .
지난 5주간 무엇을 배웠는지 돌아보고자 중간회고
테오가 강의하고 파랑이 리딩하는 함수형 프로그래밍 스터디
함수형 프로그래밍은 무엇이고,
자바스크립트는 사실 함수형 프로그래밍 언어이다.
"정확히는 우리가 아는대로 멀티 패러다임 언어입니다 ... javascript를 창시한 Brendan Erich 는 언어를 개발할 당시 유행하던 객체지향에 한계를 느끼고 LISP, scheme등 함수형 프로그래밍에 관심을 가지고 있었기에 함수형 프로그래밍의 형태로 언어를 만들고 싶어 했습니다. 하지만 Netscape의 그의 상사는 당시 개발자들이 제일 많이 쓰던 Java와 같은 문법으로 만들기 요구했기 때문에 결국 둘의 혼종의 형태로 세상에 나오게 되었습니다. :) 결국 javascript에는 언어의 태생부터 함수형 프로그래밍의 개념들이 녹아있고 동시에 객체지향의 가치는 다소 희석이 되어 있는 형태의 언어였습니다."
출처 - 테오가 쓴 글
글에는 나오지 않았지만 강의에서 테오는 자바스크립트ES6에 추가된
this가 없는 "화살표 함수" 등은 함수형 프로그래밍에 적합한 문법이라고 할 수 있다고 덧붙이셨다.
결국 우리는 javascript를 쓸 수 밖에 없기에 객체지향이냐 함수형이냐 패러다임을 선택해서 깊게 파야 하는 것이 아니라
javascript 그 자체를 잘 하기 위해서 javascript의 함수형과 객체지향을 둘 다 알아야 하는 것이다.
그래서 함수형 프로그래밍은 결국 "범위(scope)"를 기준으로 한 패러다임 중 하나 이다.
지역 변수 사용은 나쁘다고 한다.
여러 파일에서 참조 및 변경할 수 있어 에러 발생률이 높이기 때문이다.
그래서 그 범위를 "클래스"로 한정 해 사용하자, 는 것이 "객체 지향 프로그래밍" ,
이 범위를 더 좁혀 "함수"로 한정 해 사용하자, 는 것이 "함수형 프로그래밍" 이다.
함수로 범위를 좁힌 변수(지역 변수)를 사용하며,
이러한 함수들의 집합으로 프로그래밍을 완성하는 것,
그것이 함수형 프로그래밍이라 할 수 있다.
함수형 프로그래밍을 할 때 주의해야 할 점은,
이러한 전체 프로그래밍을 이루는 작은 구성원인 함수 를
가능한 작고, 테스트가 쉬우며, 분리와 재조립이 쉬운 형태 로 만드는 것이다.
이러한 함수를 만드는 법 은
바로 함수(범위) 밖의 요소에 영향을 받지도 주지도 않는 ,
즉, "순수함수"로 만드는 것 이다.
그리고 책에서는 함수를 "순수함수"로 만드는 방법에 대해 알기 쉽게 소개한다.
순수함수가 핵심이다
순수하지 않은 함수, 즉 외부에 영향을 받거나 주는 테스트가 어려운 함수를
"순수함수"라고 한다고 했다.
하지만 순수함수를 어떻게 만드는데? 라는 질문에는
선뜻 대답하기 쉽지 않은데 그 방법이 다양할 수 있기 때문이라 생각한다.
하지만 이 책에서는 한 가지 방식을 제안하는데,
바로 바뀌는 변수는 오직 인자로만 받고(명시적 입력), 전역 변수나 dom 등 다른 범위의 변수는 일정 변경하지 않는 것
이 과정에서 변경하는 데이터는 복사
또한 그렇게 함수내에서 변경된 자료는 return 으로 출력한다(명시적 출력) .
보다 구체적으로 알아보자.
저자는 바꾸는 법을 전보다 구체적으로 전달하기 위해
함수를 역할에 따라 액션, 계산, 데이터 로 3가지로 분류한다.
책에서 말하는 액션, 계산, 데이터란 아래와 같다:
액션 - 외부에 영향을 받거나 주는 함수(즉, 비순수 함수 ) 계산 - 외부에 영향을 받거나 주지 않는 함수(순수 함수 ) + 명시적인 입출력 데이터 - 그냥 데이터
결국 좋은 함수형 프로그래밍이란
비순수함수(액션)을 최대한 없애고 ,
순수함수(계산)을 최대한으로 만들어
테스트와 유지보수가 쉬운 코드를 만드는 것 이다.
또 저자는 이 과정을 보다 직관적으로 설명하기 위해
명시적 입/출력, 암묵적 입/출력의 개념을 사용한다.
명시적 입력
암묵적 입력
명시적 출력
암묵적 출력
명시적 입출력 은 필요하다
1. 테스트를 쉽게 할 뿐 아니라,
2. 테스트가 없는 경우에도 개발자에게 예측가성성이 높은 코드를 주기 때문이다.
구체적인 방법은 간단하다:
1. 계산 코드를 찾아 빼낸다.
2. 새 함수에 암묵적 입력과 출력을 찾는다.
3. 암묵적 입력은 인자로 암묵적 출력은 리턴값으로 바꾼다.
예시는 아래와 같다.
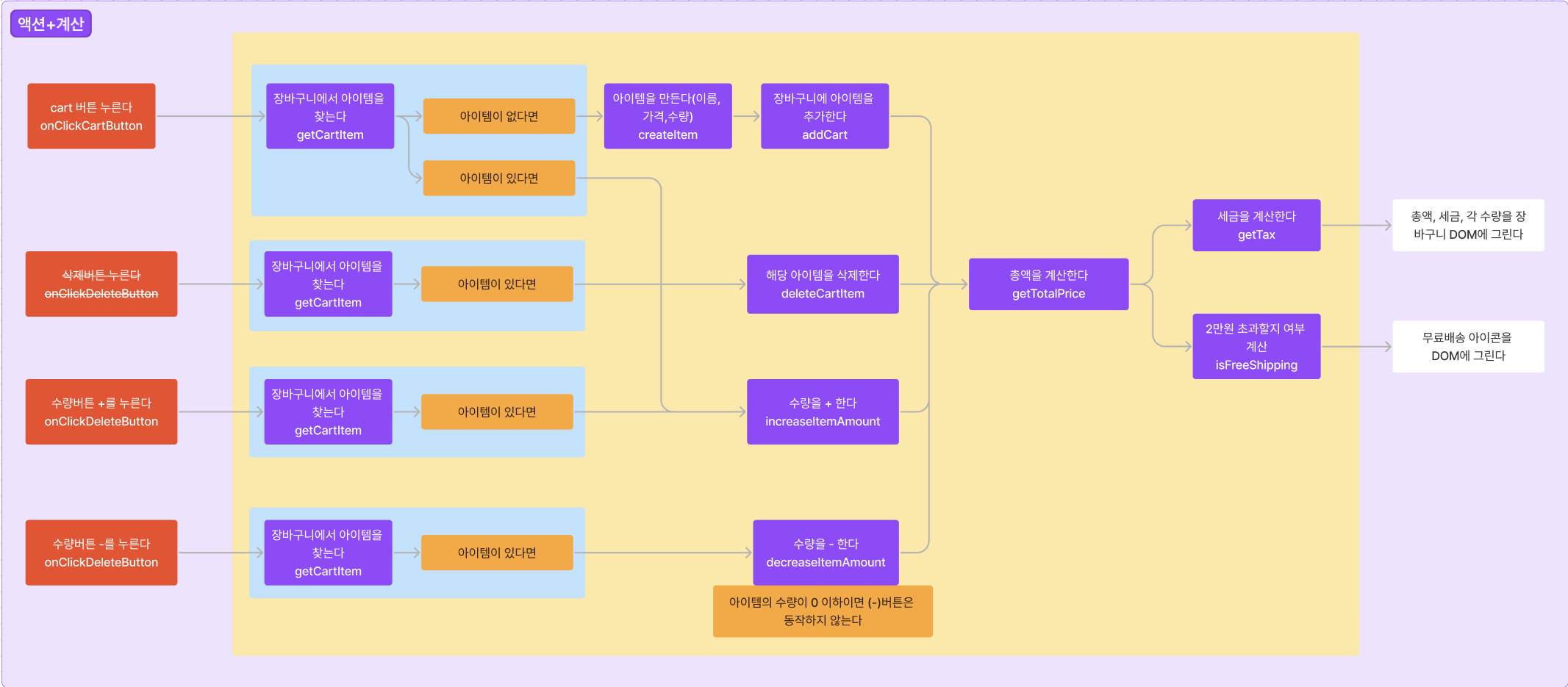
한 쇼핑몰에서 쇼핑 카트 안의 아이템들에 따라 세금을 추가하는 아래와 같은 코드가 있다.
function update_tax_dom () {
set_tax_dom(shopping_cart_total * 0.10);
}이 코드를 테스트 함수를 짠다고 생각해보라. 힘들다.
이 함수는 shopping_cart_total 이라는 외부 변수(지역 변수)를 건드리는 액션(비순수함수)이기 때문이다.
위의 코드에서 테스트 코드를 짤 수 있는 순수함수는 0개 다.
이 중에서 계산(순수함수)로 나눌 수 있는 방법은 없는지 고민해보면 아래와 같다.
// 액션 - 외부데이터(dom 등)을 변경한다.
function update_tax_dom() {
set_tax_dom(calc_tax(shopping_cart_total));
}
//계산 - 외부데이터를 일절 건드리지 않는다.(순수함수)
function calc_tax (amount) {
return amount * 0.10;
}이렇게 분리하면 calc_tax 는 순수함수이므로 테스트 코드를 짜기 쉽다.
이제 테스트 코드를 짤 수 있는 순수함수가 1개 이다.
(순수함수를 포함하고 있지만 dom도 건드리는 비순수함수도 포함하고 있는 update_tax_dom 은 비순수함수이다.
비순수 함수를 하나라도 포함하는 함수는 비순수함수이다 .)
이처럼 기존 테스트가 어려운(지역변수를 건드리고, dom을 건드리는) 함수를 테스트가 쉬운 함수(인자로 받아온 것만 변경, 명확한 결과값 return) 로 바꾸는 것. 이것이 1부 동안 리팩토링을 하며 배운 함수형 프로그래밍의 기초 이다.
다시 한 번 말하지만, 액션(비순수함수)의 사용은 불가피 하다.
프로그래밍의 목적은 데이터를 가공해 새로운 데이터를 만들어내는 데에 있기 때문이다.
그러나 유지보수가 쉽고 테스트가 쉬운 코드를 위해서는
이렇게 외부 데이터를 건드리는 함수인 액션의 사용을 '최소한' 으로 줄이고,
가능한 순수함수들로 채워넣는 데에 그 목적이 있다.
데이터의 불변성
카피-온-라이트 - 데이터 변경 시 반드시 복사한다는 원칙
데이터를 바꾸지 않고 불러오기만 하는 것을 읽기(read) 라고 한다.
데이터를 변경 하는 것을 쓰기(write) 이라고 한다.
카피-온-라이트(copy-on-write)
원본은 유지하고 복사본을 변경하라는 원칙 이다.
이렇게 함으로써 원본 데이터는 불변성을 잃지 않을 수 있다.
데이터의 불변성을 지키는 것은 중요하다 고 모두가 말한다.
불변성을 지키지 않는다면 사용할 데이터가 어디서 어떻게 바뀌어가는지 흐름을 쫓아가기 어렵고,
이는 곧 예기치 못한 side effects나 버그로 이어지게 만들기 때문이다.
이러한 불변성을 지켜주는 카피-온-라이트 방식을 사용하는 법 은 간단하다:
1. 복사본 만들기
2. 복사본 변경하기(write)
3. 복사본 리턴하기
예시와 함께 보자.
아래는 메일링 리스트에 연락처를 추가하는 코드이며,
이메일 주소를 전역변수인 리스트에 추가한다.
const mailing_list = [];
const add_contact = (email) => {
mailing_list.push(email);
}
const submit_form_handler = (event) => {
const form = event.target;
const email = form.elements["email"].value;
add_contact(email);
}전역 변수(외부 데이터)를 변경하는 것은
데이터 불변성에 어긋난다.
카피-온-라이트 방식을 이용해 불변성을 지켜보자.
const mailing_list = [];
const add_contact = (email) => {
const list_copy = [...mailing_list]; // 1. 복사한다.
list_copy.push(email); // 2. 복사본을 원하는만큼 변경한다.
return list_copy; // 3. 복사본을 리턴한다.
}
const submit_form_handler = (event) => {
const form = event.target;
const email = form.elements["email"].value;
add_contact(email);
}이제 전역 변수 mailing_list 의 원본은 변경되지 않는다.
+
"복사를 하면 비용이 많이 들지 않나요?" 라는 반박에 저자는 이렇게 대처한다.
카피-온-라이트에서 사용하는 복사는 얕은 복사(shallow copy) 이기 때문에 생각보다 비용이 많이 들지 않는다고.
이는 복사를 하지 않아 데이터의 불변성을 지키지 못할 경우 발생가능한 오류를 수정하는 비용보다 적을 것이라고 말이다.
하지만 데이터를 변경할 지도 모르는 믿을 수 없는 외부 함수(ex.남이 짠 레거시 코드) 를 사용해야만 한다면
조금 비싸더라도 깊은 복사(deep copy) 를 사용할 것을 저자는 권한다.
* 얕은 복사 vs 깊은 복사
솔직히 이 부분에 대해서는 잘 이해가 안간다.
신뢰할 수 없는 코드가 참조를 가지고 있으면 안되기 때문에 참조를 쓰지 않고 전체를 전부 복사하는 깊은 복사를 쓰는 것이라고 한다.
일단은
1. 자스에서는 lodash 를 이용해 깊은 복사 사용하면 편하며,
2. 신뢰할 수 없는 코드로 들어가는/오는 데이터는 나갈때,들어올 때 모두 깊은 복사로 감싸주어야 한다.
만 그렇구나~ 하고 받아들이기로 했다.
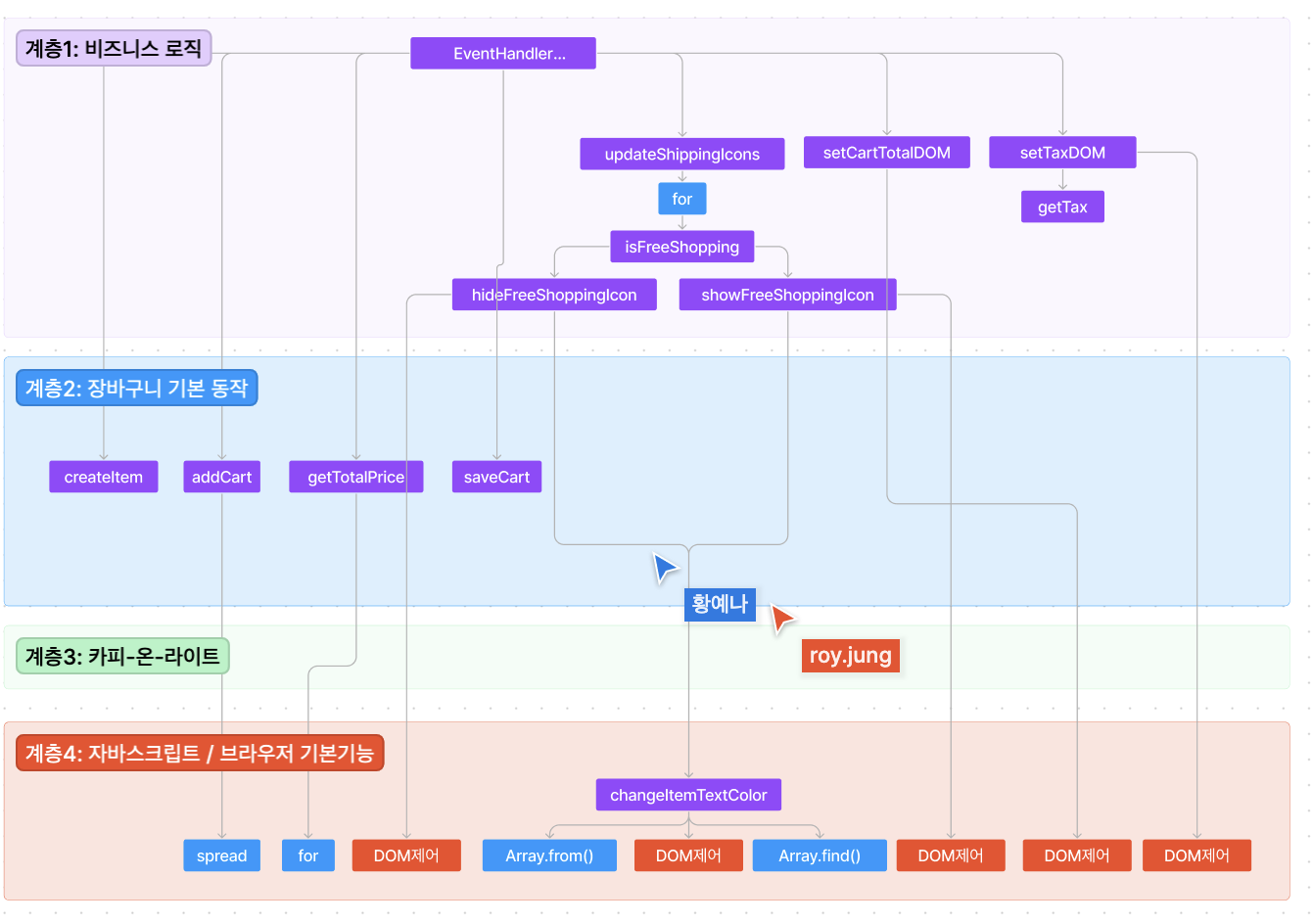
계층의 분리
계층이란 결국 추상화의 정도이다.
목적이나 추상의 정도가 같은 함수들을 같은 계층이라고 본다.
즉,
같은 계층 =
1) 같은 목적
2) 같은 구체화 수준
라고 이해했다.
계층을 나누는 데에 정답은 없다.
각자의 기준과 이유가 분명하면 된다.
계층을 나누는 감각을 기르다보면
코드를 설계하는 감각을 기를 수 있다고 한다.
아래는 우리팀이 진행한 계층의 분리이다.
이를 바탕으로 최종 리팩토링을 진행하였다.
6팀
회고 글을 쓰면서,
1. 헷갈리던 함수형 프로그래밍의 개념에 대해 제대로 이해할 수 있었다.
2. 내가 무엇을 모르는지(깊은 복사가 필요한 이유)를 확실히 할 수 있었다.
3. 계층형 설계 개념을 대충 읽었는데 다시 한 번 복습할 수 있었다.
4. 못다한 리팩토링을 회고를 쓰면서 마무리하였다.
5. 중간에 정리하는 시간을 가지며, 복습 및 정비하는 시간을 가질 수 있었다.