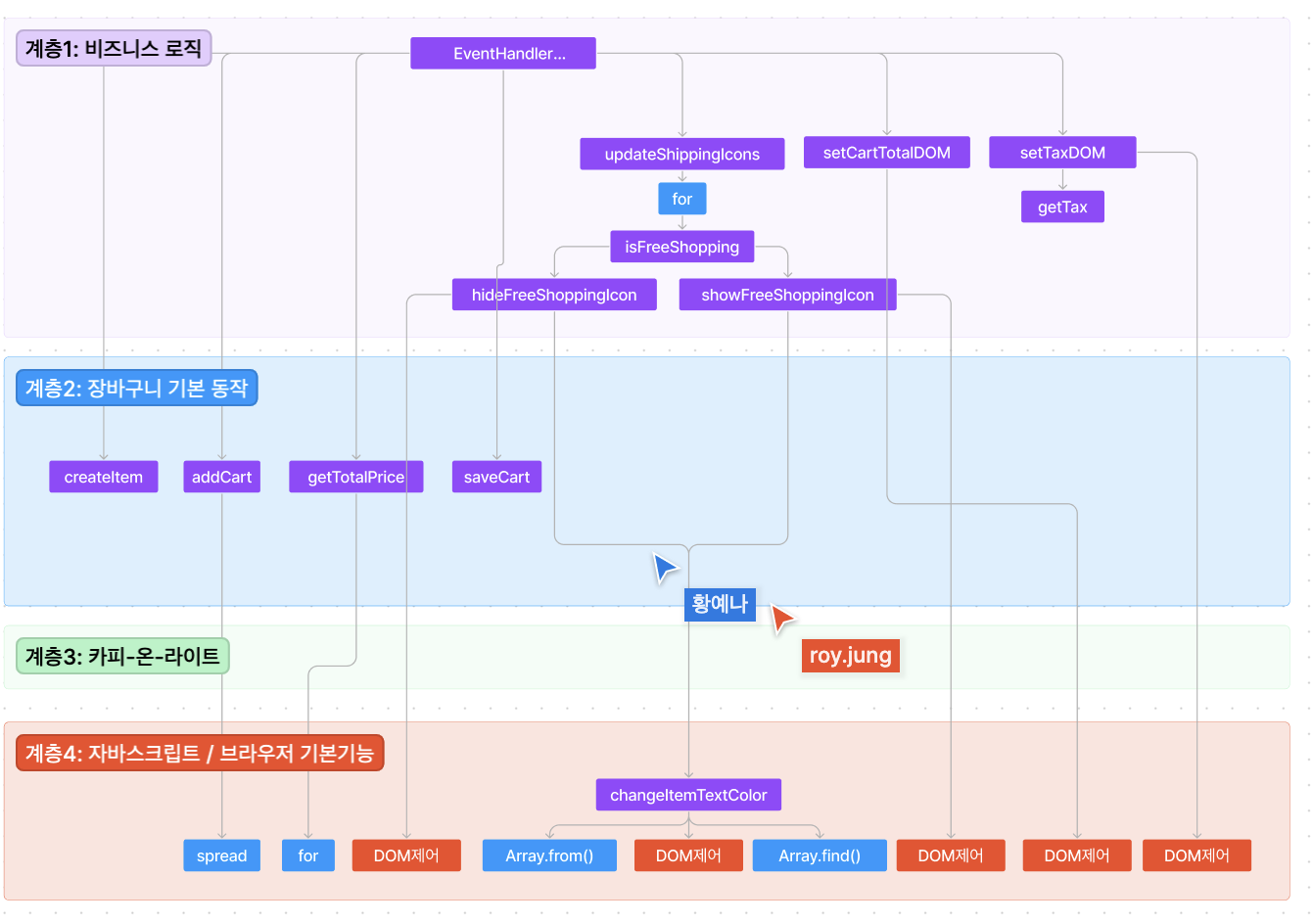
아직 후기를 쓰진 못했지만 지난 미션에서는 상태관리로 Context API를 사용했었다. Context API를 사용하며 처음전역상태관리의 개념, Context API와 다른 전역상태관리 라이브러리의 차이점에 대해 공부했었는데, 이 과정에서 전역상태관리 개념의 최초에 redux가 있다는 걸 알게 되었다.
redux에서 처음 나왔다고 알려져있는 reducer와 dispatch의 개념은 언제나 헷갈리는 개념이었다. 또 React에서 상태를 관리하는 방법에는, 요즘 뜨는 recoil, 네이티브 contextAPI, 기타 mobx... 정말 다양하다고 알려져 있지만, 앞으로 어떤 회사에 가서 어떤 상태관리 라이브러리를 사용하게 되든 근본인 redux를 배워두면 컨셉을 이해하는데 유용하지 않을까 생각했다.
그래서 사실 이번 미션의 필수 요구 사항은 오직 React(contextAPI)로만 상태관리를 하는 것이었음에도 불구하고 redux 를 택하게 되었다. 반항심리는 아니었고 근-본은 과연 어떤지, 네이티브 전역상태관리 기능인 contextAPI와는 어떤 차이가 있는지 직접 써보며 확인하고 싶었다.
Redux는 npm i redux redux-react @reduxjs/toolkit 으로 redux포함 3가지 라이브러리를 설치해야한다. 이는 최종 프로그램 번들 사이즈의 향상으로 이어진다. 반면 Context API는 다른 설치 없이 사용 가능하다.
2. 설정
Redux는 reducer, slice, store, Provider로 감싸기 등 프로그램 사용을 위해 초기 설정해줘야하는 게 많다. 반면 Context API는 context생성 Provider로 감싸주기로 초기 설정이 간단하다.
3. 데이터
Redux는 정적 및 동적 데이터 모두에 적합하다고 하는데, 그 이유는 Redux가 불변성을 유지하고 예측 가능한 방식으로 상태를 관리하도록 설계되었기 때문이다(Thinking in Redux, redux).
반면, Context API는 정적 데이터를 위해 것으로 예를 들면, 테마나 인증 정보, 사용자 언어와 같은 수준의 잘 변하지 않는 데이터를 전역적으로 공유할 때 유용하다고 한다.(when to use context, react) 따라서 Redux와 달리 복잡한 상태관리를 위한 툴은 아니라고 할 수 있겠다.
4. 확장성
Redux는 새로운 데이터나 액션을 추가할 때, 서브store 개념인 slice나 새로운 액션인 reducer를 새로 추가하면 되는 반면, context는 서브context 개념이 따로 없어 수정이 어렵다는 말로 들린다.
하지만 Context API가 보통 가장 상단이 되는 컴포넌트를 감싸는 식으로 사용되는 것과 달리, 컴포넌트와 상태를 별도의 파일로 분리해 보다 확장성 있게 사용하는 방법도 있다고 한다(How to use context effectively, Kent C. Dodds) 따라서 새로운 데이터나 액션을 추가하기 위해 컨텍스트를 처음부터 새로 짜야만한다는 이 부분에 대해서는 의구심이 든다.
5. 디버깅
Redux에서는 리덕스 개발자 도구를 처음 개발하고 배포한 개발자 중 한 명인 Zalmoxisus라는 개발자가 만든 크롬 확장 Redux DevTools이 존재한다. 아래와 같은 디버깅을 위한 다양한 기능을 제공하고, 이를 이용해 훨씬 쉽게 디버깅을 할 수 있다:
시간여행(time-travel) 기능: 과거 상태로 돌아가서 상태 변경 과정을 디버깅할 수 있습니다.
NEXTSTEP 에서 진행하는 TDD with React 2기 프로그램에 운이 좋게 참가하게 되었다.
잘 모르시는 분들을 위해 간단한 설명을 덧붙이자면, NEXTSTEP은 개발 교육 프로그램으로, 우아한형제들 개발자분들이 연사로 참여하신다. 내가 참여한 이번 TDD with React 코스는 2월 6일(월) ~ 3월 28일(화)까지 총 8주간 진행되는교육프로그램으로, TDD(Test-Driven Development)와 CDD(Component-Driven Development) 등 React로 클린코드 개발 학습을 목표로 한다.
이번주는 온보딩 미션 기간이었다. 이번 글에서는 온보딩 미션으로 리액트로계산기 구현 미션을 진행하며 배운 것을 정리해보고자 한다.
+ 추가로 파이널 미션이 있다.
미션을 진행하며 내가 배운 것들 - React 관련
이번 미션의 리뷰어님은 오태은님이셨다. 리뷰어님이 남기신 코멘트에서 다시 찾아봐야겠다 싶은 부분 중 리액트 관련 내용만 추려봤다:
1) props 에서 익명함수 가능한 자제하기
2) 컴포넌트 분리 (a.k.a 선언적이다의 뜻)
1) props 에서 익명함수 가능한 자제하기
1-1) 불필요한 레퍼런스 변경 막기
리액트에서 이벤트를 핸들링할 때 인자가 필요한 콜백함수를 넘겨주어야하는 경우가 있다. 콜백함수를 인자를 넘겨주는 방법에는 익명함수, 이벤트 객체 사용으로 2가지가 있지만, 그중 익명함수를 쓰는 것이 대표적이라고 한다. 따라서, 인자를 넘겨주는 콜백함수를 쓰는 경우를 대비해 익명함수로 콜백을 넘겨주는 걸 습관으로 들였었다.
하지만콜백을 익명함수로 넘길 경우 JSX가 호출될 때마다 새로운 함수를 생성하게 된다고 한다. 즉, 그 때마다 새로운 레퍼런스를 참조하게 되는 것이다. 계속해서 새로운 레퍼런스를 참조하게 되면 vdom을 실제dom에 반영하는 과정이나 useMemo를 사용하는 경우에 좋지 않다고 한다. 따라서 인자를 넘겨주어야 하는 콜백이 아니면 익명함수로 넘기지 않는 것이 성능상 좋다.
1-2) 객체 타입은 useMemo 와 useCallback 사용하기
첨언으로 useMemo와 useCallback에 대해서도 언급해주셨는데, 이부분은 아직 다루지 않은 개념이라 낯설어 찾아봤다. 간단히 말해, useMemo는 한 번 계산한 값을 다시 쓰는 것이고 useCallback은 한 번 사용한 함수 결과를 저장했다 재사용하는 것이다.
JSX 호출마다 객체에 대한 참조값도 계속 바뀌게 되는데, 호출마다 새로운 레퍼런스를 참조하는 것은 앞서 언급했듯 앱의 성능을 낮춘다. 따라서, object 나 array 같이 객체 사용에 있어서 useMemo 를 사용하는 것이 좋다.
2) 컴포넌트 분리 (a.k.a 선언적이다의 뜻)
리액트를 제대로 공부한지 얼마안됐지만 항상 언급되는 것이 제대로된 '컴포넌트의 분리'인듯 하다. 리액트의 핵심 개념인 컴포넌트를 어떻게 재사용가능하게 분리하는 지가 중요한가보다. 이와 관련해서는 그냥 (1)컴포넌트는 재사용이 가능해야 하고, (2)앱 전반적 비즈니스 로직별로 굵직하게 나누는게 좋다고 알고 있다. 그런데 이걸 의도해서 적용한 건 아니었고...주어진 기본 HTML의 구조가 크게 4개로 나누어지는 것 같아, 그 역할대로 나누었을 뿐이었다. 그런데 '선언적'이라는 용어를 쓰시며 뜻밖의 칭찬을 들었다. 그래서 찾아보게 되었다.
2-1) 리액트 컴포넌트 분리는 어떤 기준으로 하는 게 좋을까?
해당 물음에 대한 답을 찾아보다 FEConf2021의 원지혁님 강의와 토스슬래시의 한재엽님의 강의를 보게 되었다. 두 분의 의견에 따르면, "컴포넌트를 쪼개는 절대적 기준 같은 것은 없다. 하지만 상대적으로 잘 쪼개는 컴포넌트 분리 기준은 존재한다."는 것이었다.두 분 모두 '유지보수를 쉽게 하는'것에 기준을 두고 컴포넌트 분리를 설명하신 것이 인상 깊었다. 유지보수를 쉽게 하려면 어떻게 해야할까? 미래에 변할 수 있는 것과 상대적으로 잘 변하지 않을 것 구분하는 것이다.
원지혁님은 컴포넌트의 구성을 스타일, 로직, 전역상태, 리모드 데이터 스키마(데이터)로 분리하셨다. 유지보수를 위해 변화가 가장 잘 일어나는 데이터 모델에 따라 컴포넌트 분리를 해주는 것을 추천하셨다. 한재엽님은 변하는 것에 앞서 설명된 데이터를 데이터계산과 상호작용으로 나누셨다. 결국 둘다 데이터 관리부분인데 처음부터 제공되는 데이터냐, 사용자의 액션이 있어야 계산되는 데이터냐에 따라 한 번 더 나누신듯하다. 변하는 부분을 데이터, 변하지 않는 부분을 UI로 잡고 분리한다는 점에서 원지혁님과 의견이 같았다. 두 분 다 컴포넌트 분리의 기준을 유지보수로 잡고 계시고, 상대적으로 잘 변하는 것, 즉 컴포넌트가 다루는 데이터를 기준으로 컴포넌트를 분리하는 것을 제안하신다는 데에서 동일했다.
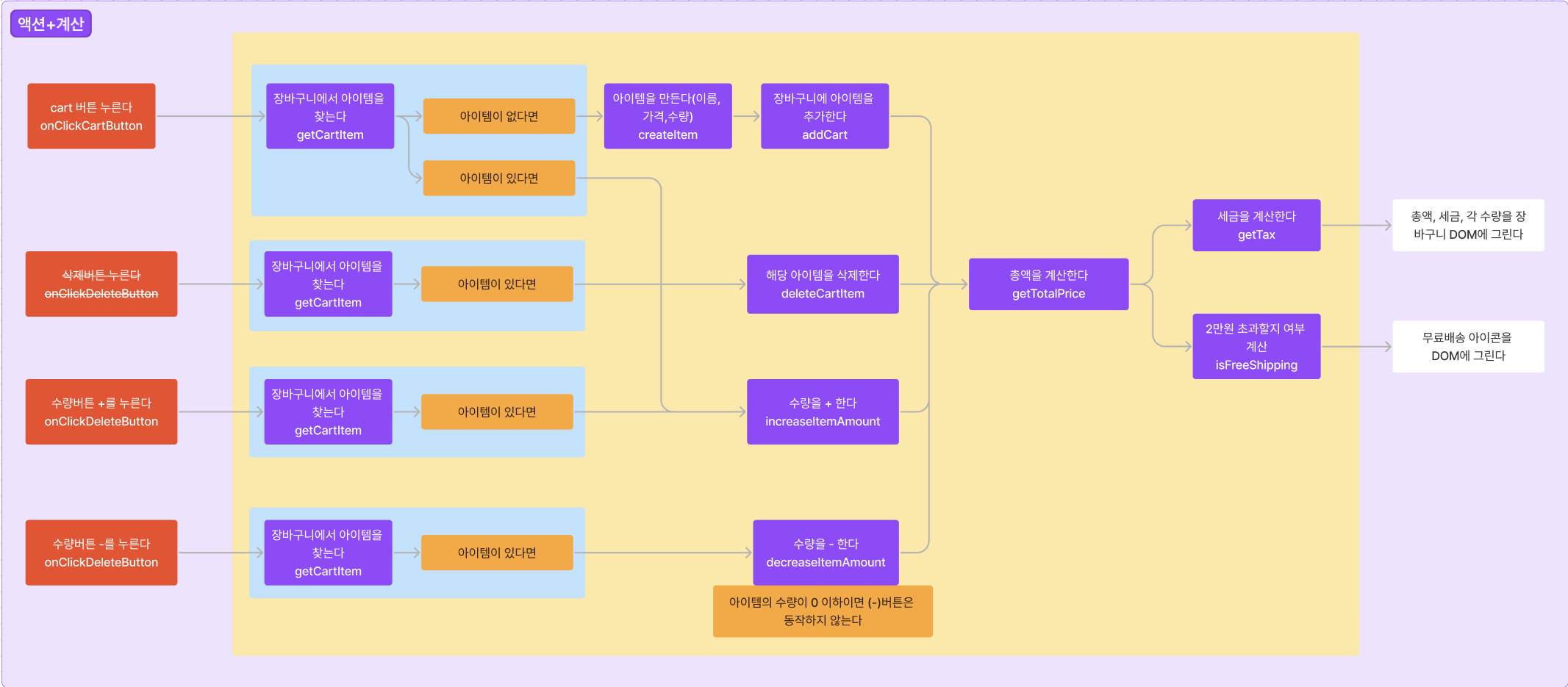
이것을 이번 계산기 모델에 적용해보았다. Total, Digits, Modifier, Operations 4가지 컴포넌트가 모두 useCalculator를 통해 calculator 데이터 모델 하나만 필요하다. calculator 모델에는 4개의 메서드 -숫자입력(addDigit), 연산자입력(addOperation), 계산(caculate), 리셋(reset)-와 상태관리 부분-현재 상태(state)와 현재 상태를 변경하는 calcReducer-가 있다. 각 컴포넌트 Total -> state.total, Digits -> addDigit, Operations -> addOperation, calculate, Modifier -> reset 에 의존하고 있다. 아마 데이터 모델을 calculator 하나에 다 때려박지 않고 각각 나눠서 정의했다고 친다면, 필요한 데이터에 따라 컴포넌트를 잘 나눈 것이기 때문에 칭찬을 받은 게 아닐까? 다만 이번 계산기 미션은 온보딩이고 작은 앱인만큼, 굳이 데이터를 여러개로 나눌 필요가 없다고 생각하셔서 데이터 모델을 분리하는 것까지는 언급하지 않으셨던게 아닐까하는 생각이 든다.
2-2) 리액트 컴포넌트 분리를 '선언적'으로 한다는 것은 어떤 의미일까?
"...컴포넌트는 선언적이다: 컴포넌트는 개발자로 하여금 어떻게(HOW)UI를 그려야 할지에 대한 고민 없이 주어진 상태에 기반해서 어(What) UI가 생겨야하는지 적기만 하면 되도록 도와준다. - Thinking in Relay
의도한 것은 아니었지만 '선언적이다'는 용어의 의미를 좀 더 명료하게 알기 위해 찾아보다보니 원지혁님의 강의가 상단에 떴다.
결국 선언적이란 건 무엇인지에 대해서만 짧게 추리자면, 선언적(Declarative)의 뜻은 누가봐도 명료하도록 컴포넌트의 분리를 나눈 것이다. 반대 개념으로 언급되는 명령형(Impertaive)가 로직의 순서대로 구현하여 흐름을 파악하기 위해 순서대로 코드를 전부 읽어야 한다면, 선언적이라는 것은 그중 공통된 주제(데이터)를 가진 로직(HOW)를 엮어 주제별(WHAT)으로 잘 뭉쳤다는 뜻인 것 같다.
사실 이렇게 컴포넌트를 나눈 것은 다른 미션수행자의 안목을 빌려온 것인데, 다음 미션부터는 어떻게 데이터를 관리하고 유저와 상호작용할 지에 대한 HOW를 고민해보고, 그 중 공통된 HOW들을 뭉쳐 WHAT 으로 잘 선언하는 설계하는 고민에 시간을 들여야겠다고 생각했다.
미션을 진행하며 내가 배운 것들 - React 외의 것들
리액트와 관련된 부분 이외의 자잘한 부분들을 정리하면 아래와 같다.
1) 왜 jsx 는 확장자를 js 로 해도 돌아가나
2) 정규식을 제대로 사용하기
3) 에러핸들링을 통해 사용자 경험 높이기
4) prettier 설정, 정확히 알고 하기:
4-1) 디폴트 설정 굳이 중복하지 말기 4-2) extend: [prettier: recommend] 4-3) VSCode 에서이 설정과 프로젝트별 설정
정규식 공부하자
에러핸들링 공부하자
마무리하며
간단한 미션인데도 복습하고 공부할 게 꽤 많았다.
리액트 문법에 대해서만 배웠던 현재 단계에서, 한 단계 더 들어가 1)리액트 최적화 2)리액트 컴포넌트 분리 등 어떻게 더 '잘' 짤 것인지에 대한 고민과 공부를 할 수 있었던 시간이었다. 이러한 면에서 리액트 '문법만' 다룰 줄 아는 학습 단계에 계신 분들께 감히 추천하고 싶다.
또 각 미션별로 이렇게 회고를 쓰는 것이 학습에 정말 많이 도움이 되었다는 구하지 않은 조언도 덧붙이고 싶다. 회고를 쓰며 '이 미션에서 얻은 것'을 정리하기 위해 리뷰를 학습 방향 지표로 삼아, 추가적으로 공부할 수 있었다. 아니었더라면 단순히 리뷰를 읽고 끝냈을 것이다...
이제 겨우 온보딩일 뿐이지만 배운 것이 많은 한 주였다. 우선 미션을 하고, 그 후 리뷰에 따라 학습하고 수정해나가나는 자세에서 진정한 Learn by Doing 을 느낄 수 있었다. 그냥 Doing 만 하면 학습효과를 이만큼 못가져간다는 걸 회고를 쓰며 깨달았다. 마지막까지도 꾸준히 배우고 회고하는 자세를 가져갈 수 있도록 노력해야겠다.
1부는 함수형 프로그래밍의 개념 및 필요성, 기초 활용법에 대해 팀으로 예제를 풀며 익히는 식으로 진행되었다.
2부부터는 쿼리 등 함수형 프로그래밍을 위해 더 함수를 잘 분리하는 심화 방법을 배운다고 한다.
매주 리팩토링 과제가 진행되며, 마지막에는 라이브러리를 만들어 보는 것으로 마무리 된다고 한다.
오늘(1/5, 2023)을 기준으로 1부가 끝이 났다.
지난 5주간 무엇을 배웠는지 돌아보고자 중간회고를 남기고자 한다.
테오가 강의하고 파랑이 리딩하는 함수형 프로그래밍 스터디
함수형 프로그래밍은 무엇이고, 우리는 왜 배워야 하는가.
자바스크립트는 사실 함수형 프로그래밍 언어이다.
"정확히는 우리가 아는대로 멀티 패러다임 언어입니다 ... javascript를 창시한 Brendan Erich는 언어를 개발할 당시 유행하던 객체지향에 한계를 느끼고 LISP, scheme등 함수형 프로그래밍에 관심을 가지고 있었기에 함수형 프로그래밍의 형태로 언어를 만들고 싶어 했습니다. 하지만 Netscape의 그의 상사는 당시 개발자들이 제일 많이 쓰던 Java와 같은 문법으로 만들기 요구했기 때문에 결국 둘의 혼종의 형태로 세상에 나오게 되었습니다. :) 결국 javascript에는언어의 태생부터 함수형 프로그래밍의 개념들이 녹아있고동시에 객체지향의 가치는 다소 희석이 되어 있는 형태의 언어였습니다."